


常见的关于堆栈以及list集合的考察方面

堆和栈的区别
堆内存用来存放由new创建的对象和数组,通过new关键字和构造器创建的对象放在堆空间,大量的对象都是放在堆空间,整个内存包括硬盘上的虚拟内存都可以被当成堆空间来使用
栈里面存放的是所有基本数据类型和引用数据类型,我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用内存中的栈空间,栈空间操作最快但是也很小
arrayList和linkedList的区别
我们知道ArrayList是List接口的一个实现类,它的特点是查询效率高,增删效率低,线程不安全
原因是因为ArrayList底层是封装了一个数组,它是用数组实现的。
看下图,数组在内存中的存储方式:
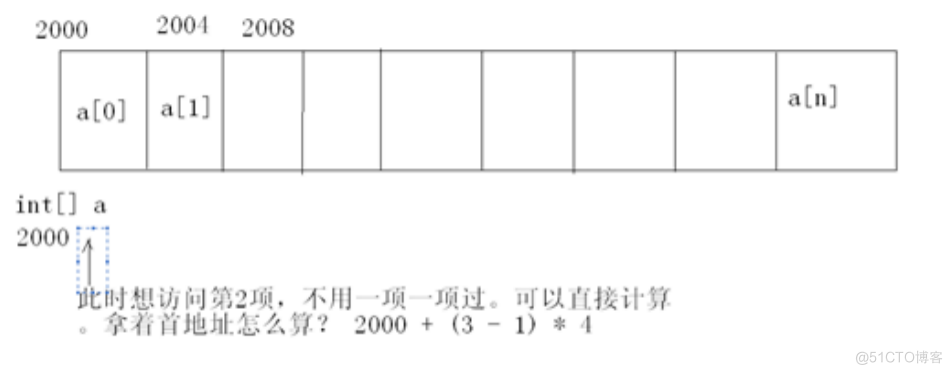
现在定义一个int[] a数组,假设它的首地址是2000,int类型占4个字节,所以a[0]的首地址是2000,a[1]的首地址就是2004,以此类推….到a[n]
所以上面的这张图,就很形象的解释了,为什么ArrayList的查询效率高,每次只需要一个偏移量就可查到
但是它的增删效率为什么会低呢?
再往下看:
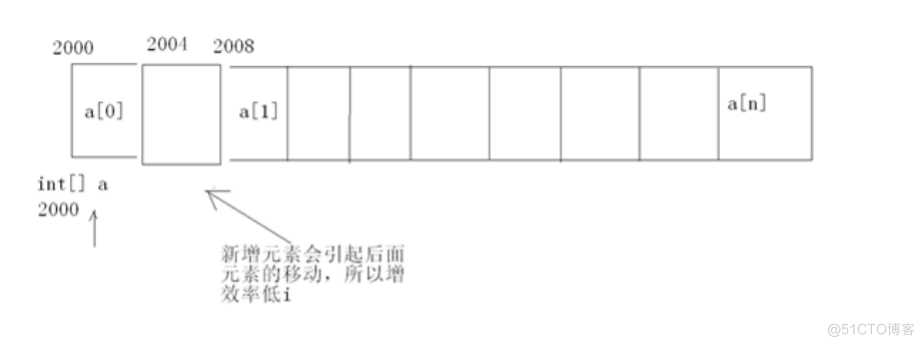
如果想在这个数组的中间或是第一项前插入一项,它的插入过程是以迭代的方式,让它后面的每一项依次往后挪,就如图上的要在第二项的位置上插入一项,其实这个过程是比较慢的,如果是你每次都在最后插入,这是个例外,因为它不用再去影响其它的元素,直接插在最后面;当然删也是同一个道理
看完了ArrayList,我们再去研究一下LinkedList
它的特点是:增删效率比较高,而查询效率低
LinkedList是底层用双向循环链表实现的List,链表的存储特点是不挨着,它存储的每个元素分为三段:上一项的地址、下一项的地址、元素的内容,而数组却没有上一项,下一项这种情况 ,因为数组只需要根据一个偏移量,就可以找到下一项或上一项
双向链表的底层结构图:
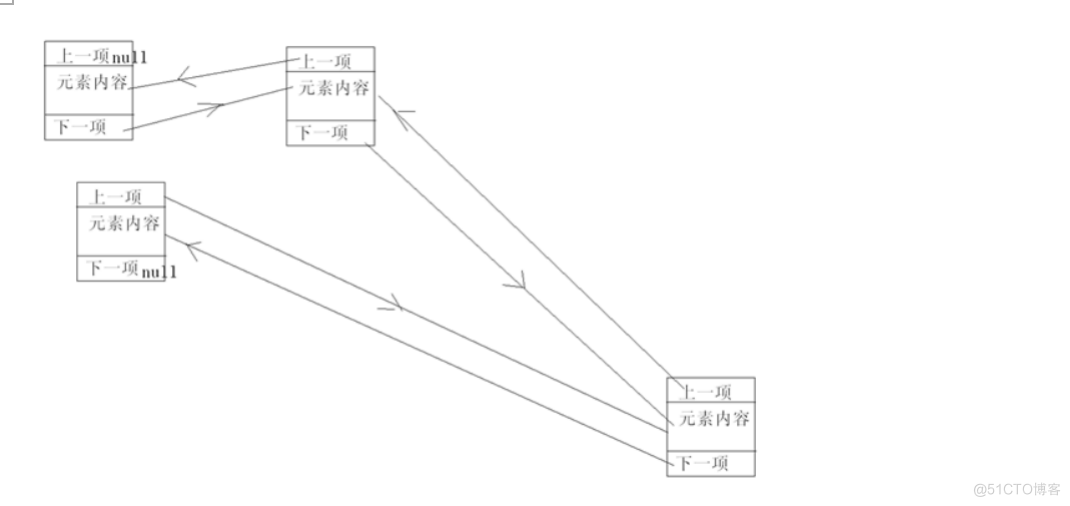
每个元素在内存中的排列像是随机的,中间没有连续性,通过地址来找到上一项或下一项,从图上应该可以理解了
那么现在问题来了,如果查询LinkedList中的某一项,肿么办?
没有好办法,只能把元素全部过一遍,这样就会比较的慢
而它的好处体现在它的增删效率非常的快,为什么呢?
看下面的图解:
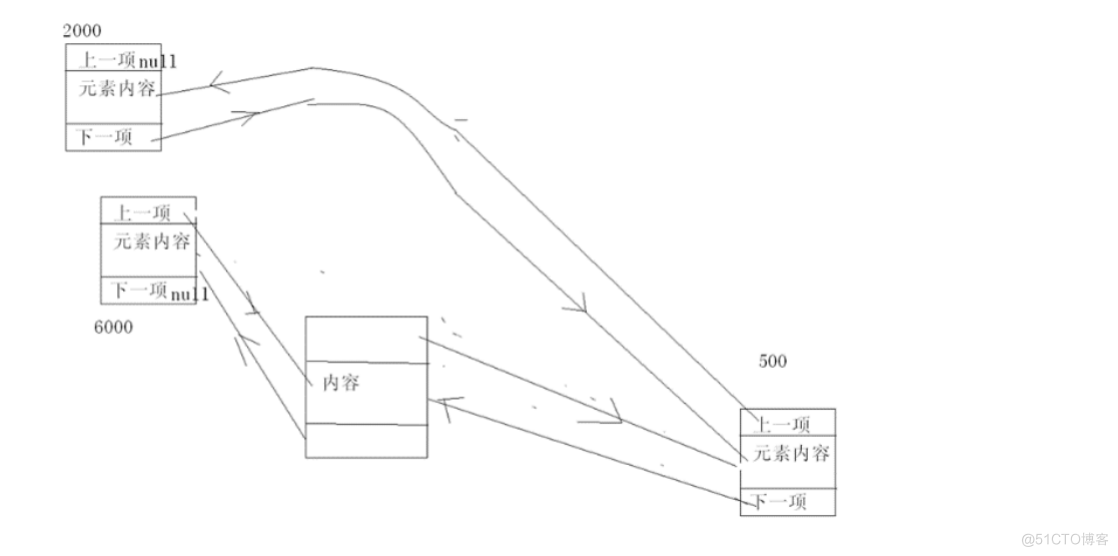
假如我把右上的一个元素删掉,可以看到左上和右下的两个元素会直接连上,至于它们两个是怎么牵上手的,这里不多讲了,你懂的…………….
同理,在下面增加一个的时候,也是同一个道理,也就是说,当你增加或删除一个元素的时候,在LinkedList里,它最多只会影响两个元素,而不像ArrayList里,当在中间插入一个元素时,它后面的所有的元素都要受到影响,那么这样在一定程度上LinkedList的增删效率就会明显的高于ArrayList的


