


超详细的 Bert 文本分类源码解读 | 附源码


本文详细的GitHub地址:
https://github.com/sherlcok314159/ML
接上一篇:
你所不知道的 Transformer!
参考论文
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1810.04805
在本文中,我将以run_classifier.py以及MRPC数据集为例介绍关于bert以及transformer的源码,官方代码基于tensorflow-gpu 1.x,若为tensorflow 2.x版本,会有各种错误,建议切换版本至1.14。
当然,注释好的源代码在这里:
https://github.com/sherlcok314159/ML/tree/main/nlp/code
章节
- Demo传参
- 跑不动?
- 数据篇
- 数据读入
- 数据处理
- 词处理
- 切分
- 词向量编码
- TFRecord文件构建
- 模型构建
- 词向量拼接
- 词向量编码
- 句子类型编码
- 位置编码
- 多头注意力
- MASK机制
- Q,K,V矩阵构建
- 损失优化
- 构建模型
- 其他注意点
Demo传参
首先大家拿到这个模型,管他什么原理,肯定想跑起来看看结果,至于预训练模型以及数据集下载。任何时候应该先看官方教程:
https://github.com/google-research/bert
官方代表着权威,更容易实现,如果遇到问题可以去issues和stackoverflow看看,再辅以中文教程,一般上手就不难了,这里就不再赘述了。
先从Flags参数讲起,到如何跑通demo。

拿到源码不要慌张,英文注释往往起着最关键的作用,另外阅读源码详细技巧可以看源码技巧:
https://github.com/sherlcok314159/ML/blob/main/nlp/source_code.md
"Required Parameters"意思是必要参数,你等会执行时必须向程序里面传的参数。
这是官方给的示例,这个将两个文件夹加入了系统路径,本人Ubuntu18.04加了好像也找不到,所以建议将那些文件路径改为绝对路径。
跑不动?
有些时候发现跑demo的时候会出现各种问题,这里简单汇总一下
1. No such file or directory! 这个意思是没找到,你需要确保你上面模型和数据文件的路径填正确就可解决
2. Memory Limit
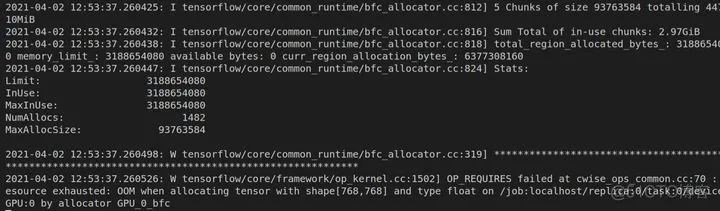
因为bert参数量巨大,模型复杂,如果GPU显存不够是带不动的,就会出现上图的情形不断跳出。
解决方法
- 把batch_size,max_seq_length,num_epochs改小一点
- 把do_train直接false掉
- 使用优化bert模型,如Albert,FastTransformer
经过本人实证,把参数适当改小参数,如果还是不行直接不做fine-tune就好,这对迅速跑通demo的人来说最有效。
数据篇
这是很多时候我们自己跑别的任务最为重要的一章,因为很多时候模型并不需要你大改,人家都已经给你训练好了,你在它的基础上进行优化就好了。而数据如何读入以及进行处理,让模型可以训练是至关重要的一步。
数据读入

简单介绍一下我们的数据,第一列为Quality,意思是前后两个句子能不能匹配得起来,如果可以即为1,反之为0。第二,三两列为ID,没什么意义,最后两列分别代表两个句子。
接下来我们看到DataProcessor类,(有些类的作用仅仅是初始化参数,本文不作讲解)。这个类是父类(超类),后面不同任务数据处理类都会继承自它。它里面定义了一个读取tsv文件的方法。
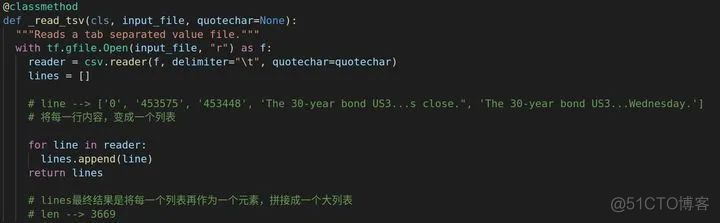
首先会将每一列的内容读取到一个列表里面,然后将每一行的内容作为一个小列表作为元素加到大列表里面。
数据处理
因为我们的数据集为MRPC,我们直接跳到MrpcProcessor类就好,它是继承自DataProcessor。
这里简要介绍一下os.path.join。

我们不是一共有三个数据集,train,dev以及test嘛,data_dir我们给的是它们的父目录,我们如何能读取到它们呢?以train为例,是不是得"path/train.tsv",这个时候,os.path.join就可以把两者拼接起来。

这个意思是任务的标签,我们的任务是二分类,自然为0&1。
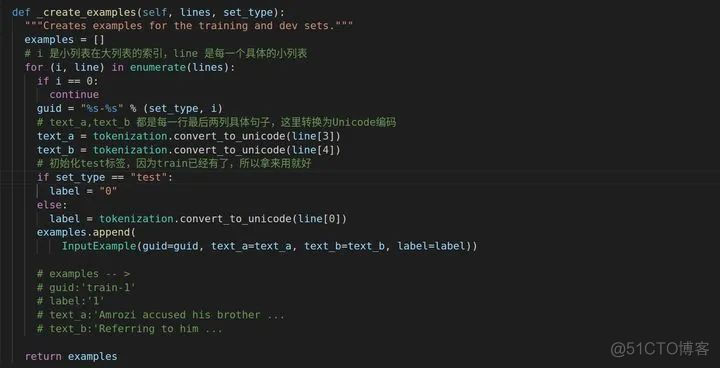
examples最终是列表,第一个元素为列表,内容图中已有。
词处理
读取数据之后,接下来我们需要对词进行切分以及简单的编码处理
切分

label_list前面对数据进行处理的类里有get_labels参数,返回的是一个列表,如["0","1"]。
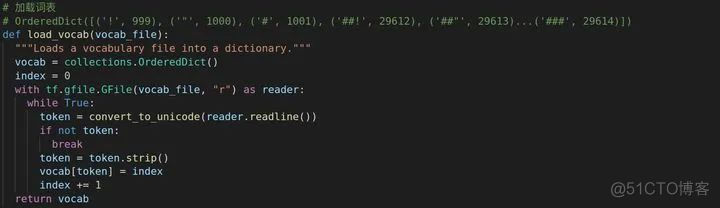
想要切分数据,首先得读取词表吧,代码里面一开始创造一个OrderedDict,这个是为什么呢?
在python 3.5的时候,当你想要遍历键值对的时候它是任意返回的,换句话说它并不关心键值对的储存顺序,而只是跟踪键和值的关联程度,会出现无序情况。而OrderedDict可以解决无序情况,它内部维护着一个根据插入顺序排序的双向链表,另外,对一个已经存在的键的重复复制不会改变键的顺序。
需要注意,OrderedDict的大小为一般字典的两倍,尤其当储存的东西大了起来的时候,需要慎重权衡。
但是到了python 3.6,字典已经就变成有序的了,为什么还用OrderedDict,我就有些疑惑了。如果说OrderedDict排序用得到,可是普通dict也能胜任,为什么非要用OrderedDict呢?
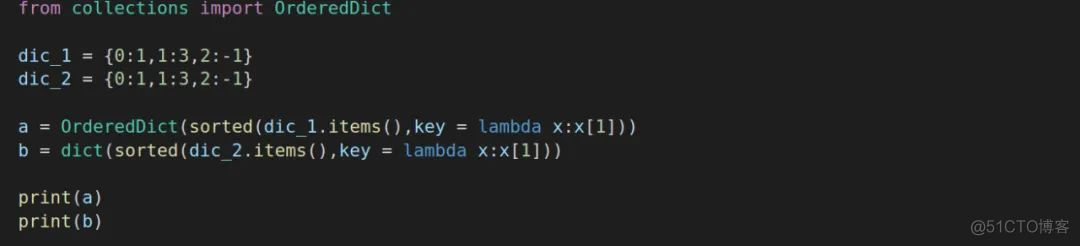
在tokenization.py文件中提供了三种切分,分别是BasicTokenizer,WordpieceTokenizer和FullTokenizer,下面具体介绍一下这三者。
在tokenization.py文件中遍布convert_to_unicode,这是用来转换为unicode编码,一般来说,输入输出不会有变化。
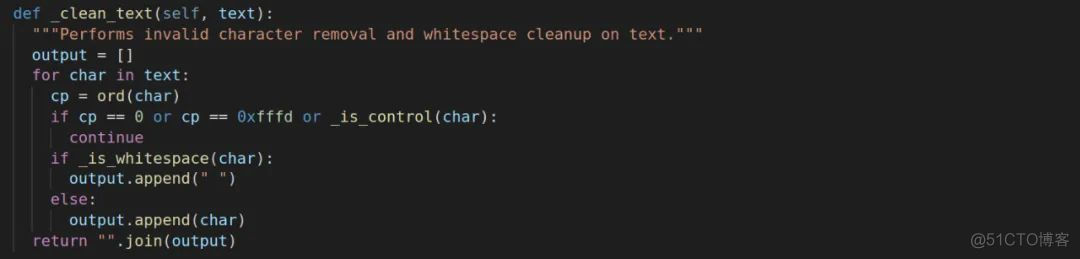
这个方法是用来替换不合法字符以及多余的空格,比如\t,\n会被替换为两个标准空格。接下来会有一个_tokenize_chinese_chars方法,这个是对中文进行编码,我们首先要判断一下是否是中文字符吧,_is_chinese_char方法会进行一个判断。
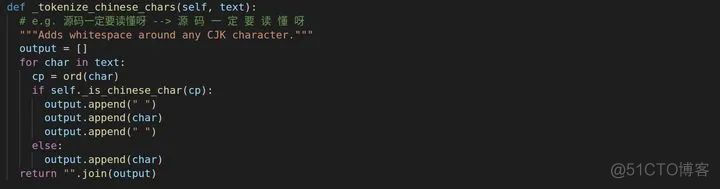
如果是中文字符,_tokenize_chinese_chars会将中文字符旁边都加上空格,图中我也有引例注释。

whitespace_tokenize会进行按空格切分。

_run_strip_accents会将变音字符替换掉,如résumé中的é会被替换为e。
接下来进行标点字符切分,前提是判断是否是标点吧,_is_punctuation履行了这个职责,这里不再多说。
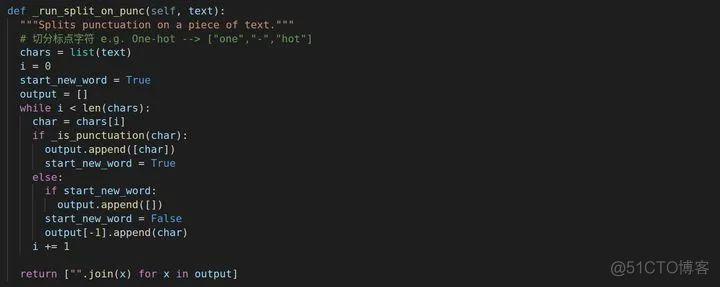
以上便是BasicTokenizer的内容了。
接下来是WordpieceTokenizer了,其实这个词切分是针对英文单词的,因为汉字每个字已经是最小的结构,不能进行切分了。而英文还可以进行切分,英文有不同语态,如loved,loves,loving等等,这个时候WordpieceTokenizer就能发挥作用了。
- 遍历一个英文单词里面的小结构,如果发现在词表里找到,就把这个切掉
- 对未被切分的部分继续进行步骤一,直至所有都被切分干净,注意除了第一个,其他的前面都要加上"##"
下面有个gif可以直观显示,来源:
https://alanlee.fun/2019/10/16/bert-tokenizer/

最后是FullTokenizer,这个是两者的集成版,先进行BasicTokenizer,后进行WordpieceTokenizer。当然了,对于中文,就没必要跑WordpieceTokenizer。

下面简单提一下convert_by_vocab,这里是将具体的内容转换为索引。

以上就是切分了。
词向量编码
刚刚对数据进行了切分,接下来我们跳到函数convert_single_example,进一步进行词向量编码。

这里是初始化一个例子。input_ids 是等会把一个一个词转换为词表的索引;segment_ids代表是前一句话(0)还是后一句话(1),因为这还未实例化,所以is_real_example为false。

此处tokenizer.tokenize是FullTokenizer的方法。
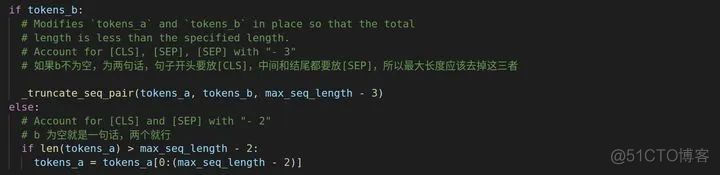
不同的任务可能含有的句子不一样,上面代码的意思就是若b不为空,那么max_length = 总长度 - 3,原因注释已有;若b为空,则就需要减去2即可。
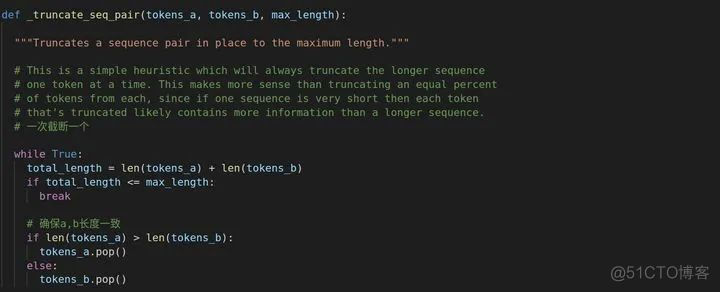
_truncate_seq_pair进行一个截断操作,里面用了pop(),这个是列表方法,把列表最后一个取出来,英文注释也说了为什么没有按照比例截断,若一个序列很短,那按比例截断会流失信息较多,因为比例是长短序列通用的。同时,_truncate_seq_pair还保证了a,b长度一致。若b为空,a则不需要调用这个方法,直接列表方法取就好。
我们不是说需要在开头添加[CLS],句子分割处和结尾添加[SEP]嘛(本次任务a,b均不为空),刚刚只是进行了一个切分和截断操作。
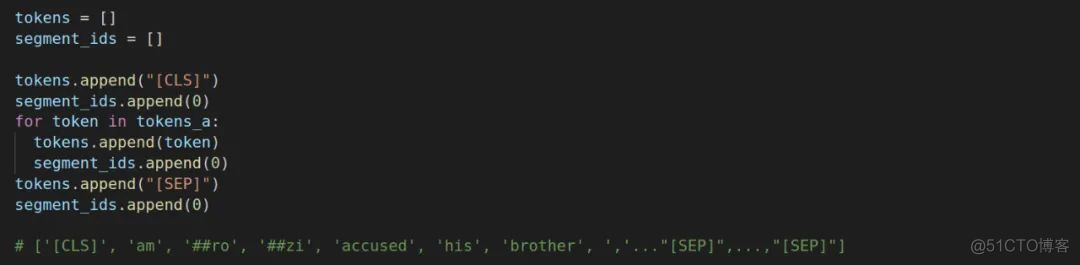
tokens是我们用来放序列转换为编码的新列表,segment_ids用来区别是第一句还是第二句。这段代码大意就是在开头和结尾处加入[CLS],[SEP],因为是a所以都是第一句,segment_ids就都为0,同时[CLS]和[SEP]也都被当做是a的部分,编码为0。下面关于b的同理。
接下来再把具体内容转换为索引。

我们一开始的参数不是有max_seq_length嘛,这个代表一整个序列的最大长度(a,b拼接的),但是很多时候我们的总序列长度不会达到最大长度,但是我们又要保证所有输入序列长度一致,即为最大序列长度。所以我们需要对剩下的部分,即没有内容的部分进行填充(Padding),但填充的时候有个问题,一般我们都会添0,但做self-attention的时候(如果还不了解自注意力,可以去主页看看我写的Transformer的论文解读),每一个词要跟句子里面所有的词做内积,但是0是我们人为填充进去的,它不代表任何意义,然而,做自注意力的时候还是要跟它做内积,是不是不太合理呀?
于是就有了MASK机制,什么意思呢?我们把机器需要看,需要做自注意力的保留,不要看的MASK掉,这样做自注意力的时候就不会出岔子。
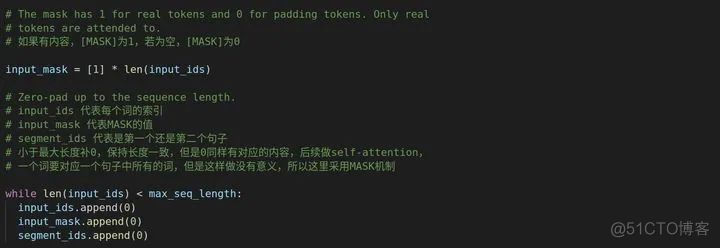
同时,只要没达到最大长度,就全部补零。
这个的剩余部分tf.logging是日志,不用管,这个convert_single_example最终返回的是feature,feature包含什么已经具体阐述过了。
TFRecord文件构建
因为用TFRecord读取文件比较方便快捷,需要转换一下文件格式。

前半部分是examples写入,examples是来自上图方法。features是来自上面刚讲过的convert_single_example方法。
需要注意的是这份run_classifier.py人家谷歌是用TPU跑的,所以会有TPU部分代码,一般我们只用GPU,所以TPU部分不需要关注,一般TPU都会出现TPUEstimator。
模型构建
接下来,是构建模型篇,是整个代码中最重要的一部分。接下来我将用代码介绍一下transformer模型的架构。
找到modeling.py文件,这是模型文件。
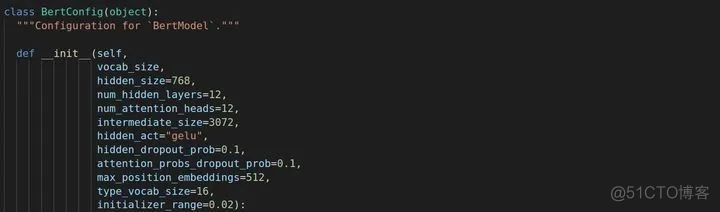
首先是BertConfig的类,这里自定义了一些参数及数值。

后面 batch_size x seq_length 会经常出现,这里是原始定义 这里还有个初始化,如果MASK和token_type_ids我们前面没有,这里就默认全为1和0。这是为了后面词嵌入(embedding)做准备。

词向量拼接
接下来正式进入Embedding层的操作,最终传到注意力层的其实是原始token_ids,token_type_ids以及positional embedding拼接起来的。
token_ids编码
首先是token_ids的操作,先来看一下embedding_lookup方法。
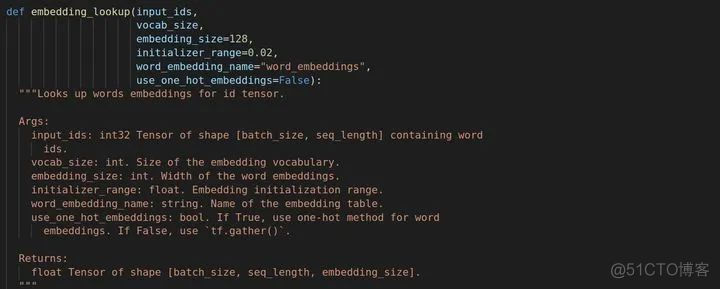
这是它的参数,大部分英文注释已有,需要注意的一点是input_ids的shape必须为[batch_size,max_seq_length]。
接下来进行扩维。

等会我们需要在embedding_table里面查找,这里先构建一个[vocab_size,embedding_size]的table。需要注意的是vocab_size 和 embedding_size 都是固定好的,训练的时候不能乱改。

之后我们对input_ids进行降维,貌似这样可以加速。one_hot_embedding一般为false,这是对TPU加速用的。接下来在embedding_table里面进行查找。

然后我们把output reshape一下。

这就是token的编码了。
句子类型编码
进行位置编码之前,我们首先进行对token_type_ids的编码(判断是哪一句)。
首先创建token_type_table。

然后进行一个token_type_embedding,matul是矩阵相乘
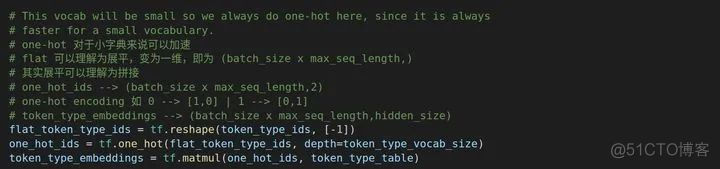
做好相乘之后,我们需要把token_type_embedding的shape还原,因为等会要将token_type_ids与词编码相加。

位置编码
首先我们先创造大量的位置,max_position_embeddings是官方给定的参数,不能修改。

我们创造了这么多的位置,最终不一定用的完,为了更快速的训练,我们一般做切片处理,只要到我的max_seq_length还有位置就好,后面都可以不要。

前面要把token_type_embeddings加到input_ids的编码中,进行了同维度处理,这里对于位置编码也一样,不然最后相加不了。
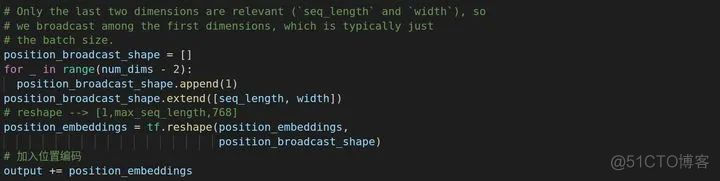
至此,Embedding层就结束了。Transformer论文不是说了嘛,在加入位置编码之前会进行一个Dropout操作

多头机制
接下来来到整个transformer模型的精华部分,即为多头注意力机制。
MASK机制
首先来到create_attention_mask_from_input_mask方法,from_seq_length和to_seq_length分别指的是a和b,前面讲关于切分的时候已经说了,切分处理会让a,b长度一致为max_seq_length。所以这里两者长度相等。最后创建了一个shape为(batch_size,from_seq_length,to_seq_length)的MASK。又扩充了一个维度,那这个维度用来干什么呢?我们一开始不是说了吗?自注意的时候需要将填充的部分遮掉,那么多余的维度干的就是这个事。比如我们设置最大长度为8,句子长度为6,那么有一个维度是[1,1,1,1,1,1,0,0]。

Q,K,V矩阵
构建首先来到attention_layer方法,q,k,v矩阵的激活函数均为None。
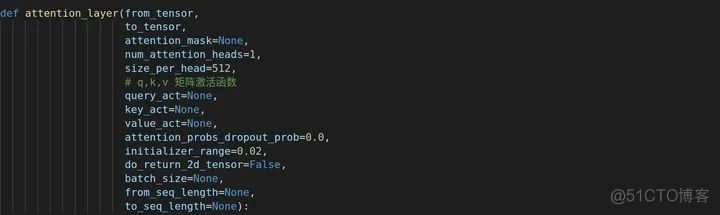
在进入构建之前,最好先熟悉这5个字母的含义。

开始构建q矩阵,注意q是由from_tensor,即第一个句子构建的。

接着构建k和v矩阵,都是从to_tensor构建的。


接下来会对q,k矩阵进行加速内积处理,不做深入探讨。

记得我们在transformer里面需要除以d的维度开根号。

attention_mask即为上节我们说的MASK,这里进行拓展一个维度。

这里再简要介绍一下adder。tf.cast方法只是转换数据类型,这里用x代表attention_mask,(1-x)* (-1000)的目的是当attention为1时,即要关注这个,那么(1-x)就越趋近于0,那么做softmax,值就越接近于0,类似地,如果attention为0,那么进过softmax后的值就更接近-1。最后把这个adder加到刚刚我们得到注意力的值,估计这里会有人搞不懂为什么怎么做。
果关联度很高,那么attention_scores就越接近1,越低,越接近0,但是,很可能是我们补零的部分,所以我们需要对这个进行处理,这里有两种思路,既然是补零的,我们直接去掉就好;或者这里谷歌的做法是如果不需要,直接-1,是不是注意力值就趋近于0了,如果需要,加了0本身值不会发生变化。经过谷歌验证,后者效率更高。

接下来进行transformer模型构建,不难发现这里from_tensor和to_tensor一致,所以是做自注意力。
损失优化
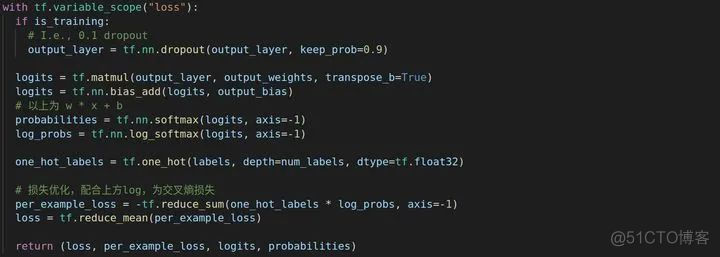
在bert里面说过,最后拿出开头的[CLS]就可以了。这既是get_pooled_output方法的作用。

最后再连接一个全连接层,最后就是二分类的任务w * x + b
模型构建
model_fn方法是构建的函数之一,一定一定要小心,虽然上面写着返回给TPUEstimator,可如果你运行过demo的话,输出的很多东西都来源于这个方法。

进入main(_)主方法,需要注意的是,以后我们需要fine-tune,需要把我们自己定义的processor添加进processors。

确认要训练之后,会计算需要一共多少步完成,这里还有个warm-up,意思是一开始呢让learning rate低一下,等到了warm-up proportion之后再还原。

终于我们开始构建模型了

最终我们构建了estimator用于后期训练,评估和预测

其他注意点
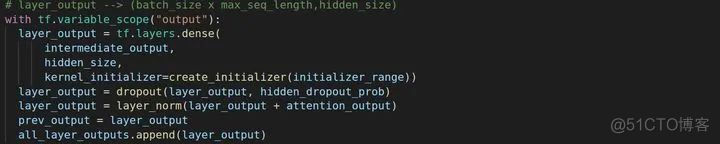
这是残差相连的部分

还有一点就是记得在transformer中讲过我们会连两层全连接层,一层升维,另一层降维。

接下来进行降维
觉得写的好,不妨去github上给我star,里面有很多比这还要棒的解析:
https://github.com/sherlcok314159/ML


