


使用文本图像生成工具TextRecognitionDataGenerator来生成文本图像数据

相关标签: # python# git# github# windows# 工具
windows10系统,python3.9的环境:
文本生成工具代码:github上有:TextRecognitionDataGenerator
1、首先准备自己的字体文件和文本背景图像:
2、准备好数据字符列表文件:注意txt文件是utf-8的编码格式。
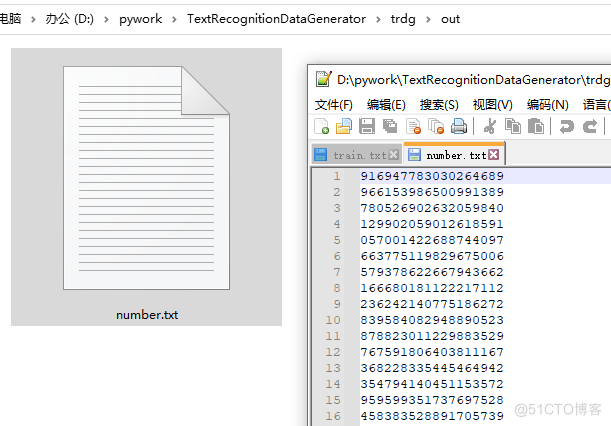
3、可以使用脚本生成列表文件,这里是号码生成举例:
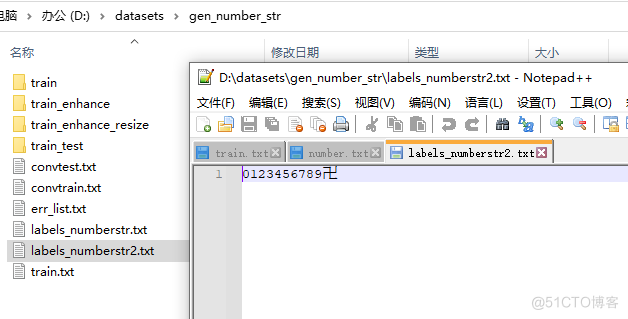
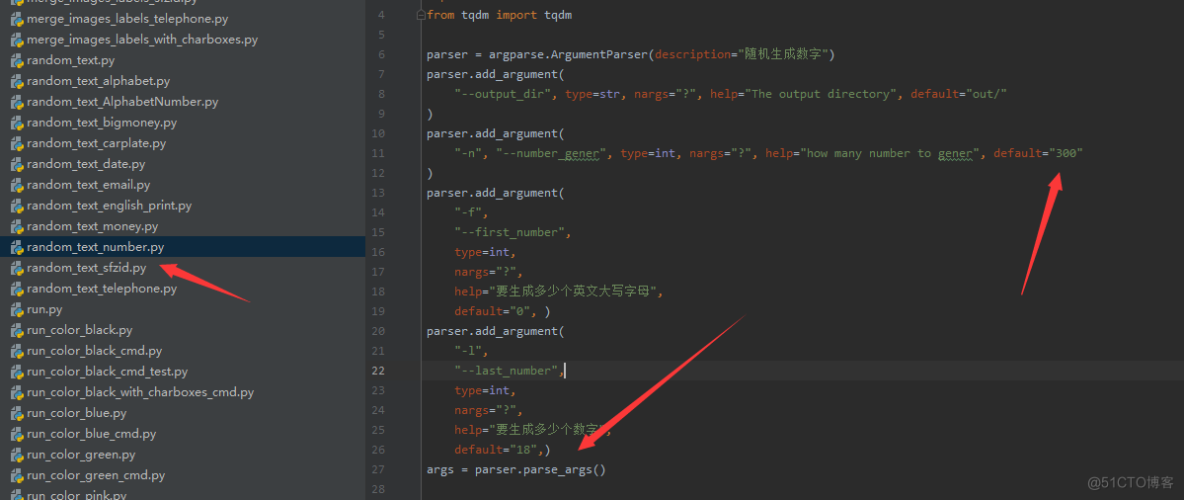
import random, string
import argparse
import os
from tqdm import tqdm
parser = argparse.ArgumentParser(description="随机生成数字")
parser.add_argument(
"--output_dir", type=str, nargs="?", help="The output directory", default="out/"
)
parser.add_argument(
"-n", "--number_gener", type=int, nargs="?", help="how many number to gener", default="300"
)
parser.add_argument(
"-f",
"--first_number",
type=int,
nargs="?",
help="要生成多少个英文大写字母",
default="0", )
parser.add_argument(
"-l",
"--last_number",
type=int,
nargs="?",
help="要生成多少个数字",
default="18",)
args = parser.parse_args()
out_dir = args.output_dir
number_gener = args.number_gener
if not os.path.exists(out_dir):
os.makedirs(out_dir)
std_chinese_label = r'D:\datasets\gen_number_str\labels_numberstr2.txt'
char_set = open(std_chinese_label, 'r', encoding='utf-8').readlines()
std_char_set = ''.join(char_set)
# 创建一个标签字典
labelstr = ' '.join(char_set)
lable_dict = dict.fromkeys(labelstr, 0)
with open(os.path.join(out_dir, 'number.txt'), 'w') as f:
for i in tqdm(range(number_gener)):
passwd1 = []
uppercase = string.ascii_uppercase
lowercase = string.ascii_lowercase
digits = string.digits
length_uppercase = len(uppercase)
length_digits = len(digits)
for i in range(args.first_number):
latter = uppercase[random.randint(0, length_uppercase - 1)]
passwd1.append(latter)
for i in range(args.last_number):
latter = digits[random.randint(0, length_digits - 1)]
currentcharidxV = std_char_set.find(latter)
if currentcharidxV == -1:
continue
# 检测字符 是否存在 字典中
if latter in lable_dict:
lable_dict[latter] = lable_dict[latter] + 1
if lable_dict[latter] > 5000:
continue
passwd1.append(latter)
if len(passwd1):
f.write("".join(passwd1))
f.write('\n')
# print("".join(passwd1))
print(str(lable_dict))
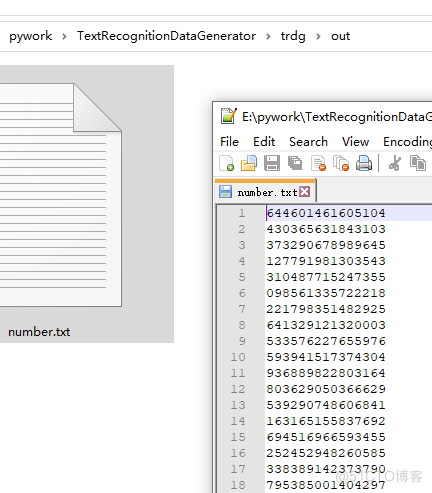
4、准备好列表文件后,开始运行生成工具脚本进行文本图像的生成:
先指定字体颜色:

然后使用如下脚本运行,在out目录下生成文本图像:
import os
import cv2
import glob
import pathlib
import random
# 使用python来批量执行cmd命令,生成图像数据
images_num = 200
for ttf_file in glob.glob('fonts/cn/*.ttf', recursive=True):
tfile = pathlib.Path(ttf_file)
if os.path.exists(ttf_file):
print(ttf_file)
else:
print('不存在', ttf_file)
continue
ttfname = str(tfile.stem)
ttfsuffix = str(tfile.suffix)
ttfnamewithsuffix = ttfname + ttfsuffix
if ttfname != 'mao':
cmd_str = 'python run_color_black.py -c ' + str(
images_num) + ' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 1 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_01/ -na 2'
os.system(cmd_str)
else:
cmd_str = 'python run_color_black.py -c ' + str(
images_num) + ' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 5 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_02/ -na 2'
os.system(cmd_str)
# 加倾斜
if ttfname != 'mao':
cmd_str = 'python run_color_black.py -c ' + str(
images_num) + ' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 1 -k 5 -rk -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_03/ -na 2'
os.system(cmd_str)
else:
cmd_str = 'python run_color_black.py -c ' + str(
images_num) + ' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 5 -k 5 -rk -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_04/ -na 2'
os.system(cmd_str)
# # 波浪形,高斯噪声
# if ttfname != 'mao':
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 1 -k 5 -rk -d 1 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_05/ -na 2'
# os.system(cmd_str)
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 1 -k 5 -rk -d 2 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_06/ -na 2'
# os.system(cmd_str)
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 1 -k 5 -rk -d 3 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_07/ -na 2'
# os.system(cmd_str)
# else:
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 5 -k 5 -rk -d 1 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_08/ -na 2'
# os.system(cmd_str)
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 5 -k 5 -rk -d 2 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_09/ -na 2'
# os.system(cmd_str)
# cmd_str = 'python run_color_black.py -c '+str(images_num)+' -w 5 -f 64 -b 3 -t 8 -bl 1 -rbl -cs 5 -k 5 -rk -d 3 -ft fonts/cn/' + ttfname + '.ttf -id images -i out/number.txt --output_dir out/out_black_' + ttfname + '_10/ -na 2'
# os.system(cmd_str)
生成图像:
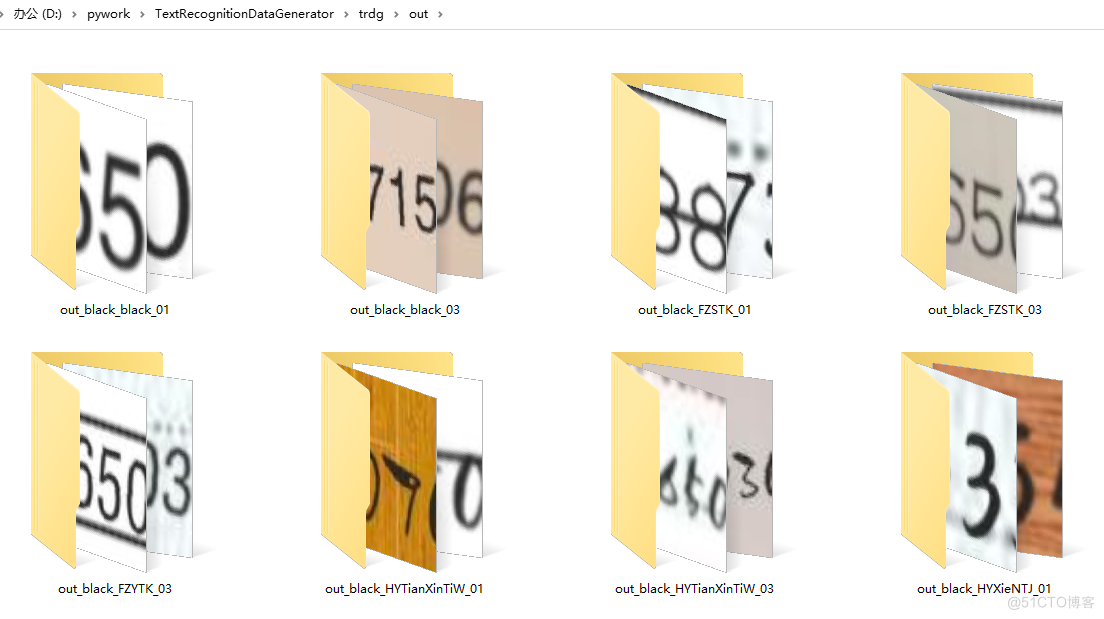
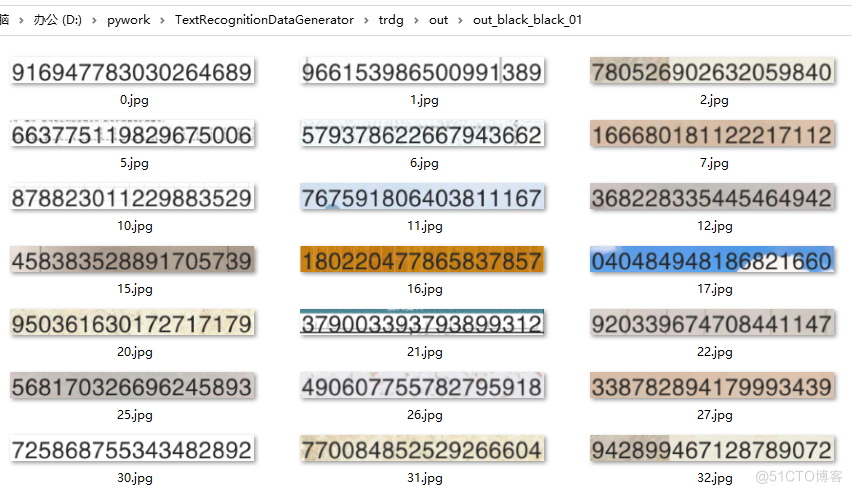
还有文本信息的lables.txt文件:
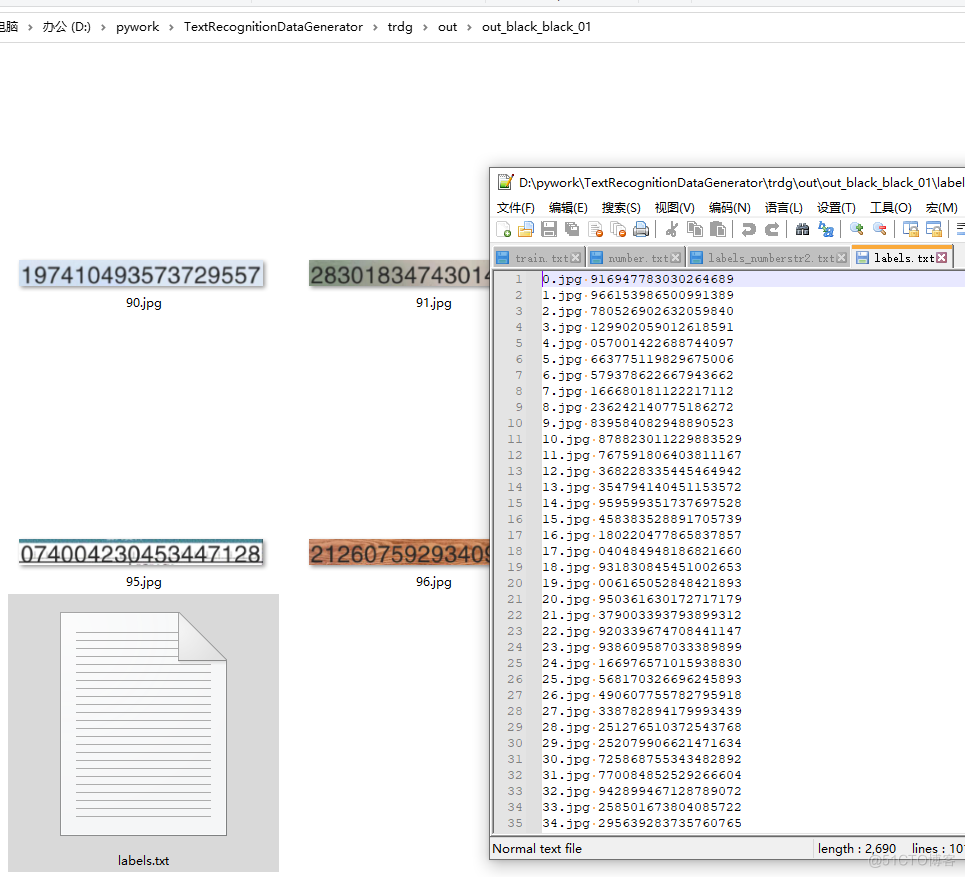
注意在生成文本图像是要检查一下图像数据是否有问题,因为有的字体ttf文件不支持某些字符,从而导致生成图像中有空白或者方框,这都是错误数据,及时纠正。
5、生成完数据后,可以转移图像数据,并生成对应的图像列表文件了:这里是数字数据集为例
import os
import pathlib
import sys
import shutil
from pathlib import Path
def find_labels(rootdir, labels):
labels_list = []
for root, dirs, files in os.walk(rootdir):
for dir in dirs: # 遍历目录里的所有文件夹
print(os.path.join(root, dir), " --- dir")
for file in files: # 遍历目录里的所有文件
if file.endswith(labels):
print(os.path.join(root, file), " --- file")
label_file = os.path.join(root, file)
labels_list.append(label_file)
return labels_list
#
if __name__ == '__main__':
dir = Path(r'D:\pywork\TextRecognitionDataGenerator\trdg\out')
traindir = 'D:\\datasets\\gen_number_str'
if not os.path.exists(traindir):
os.makedirs(traindir)
copy2dir = 'D:\\datasets\\gen_number_str\\train'
if not os.path.exists(copy2dir):
os.makedirs(copy2dir)
# src = sys.argv[1]
labels_files = find_labels(dir, 's.txt')
cnt = 0
train_file = open(traindir + '\\train.txt', 'a', encoding='utf-8-sig') # 带BOM的UTF-8格式
for label in labels_files:
current_images_path = os.path.split(label)
with open(label, "r", encoding='utf8') as f:
for line in f.readlines():
line = line.strip('\n') # 去掉列表中每一行元素的换行符
lineData = line.split(' ',1) #以第一个空格进行分割,一分为二
image = lineData[0]
textVal = lineData[1]
img = pathlib.Path(image)
imagename = str(img.stem)
imagesuffix = str(img.suffix)
imgnamewithsuffix = imagename + imagesuffix
current_image_file = current_images_path[0] + '\\' + imgnamewithsuffix
if os.path.exists(current_image_file):
print(current_image_file)
else:
print('不存在', current_image_file)
continue
cnt = cnt + 1
print(cnt)
copy_rename_file = copy2dir + '\\number_images_' + str(cnt) + '.jpg'
shutil.copy(current_image_file, copy_rename_file)
train_file.write(copy_rename_file + '\t' + textVal + '\t' + 'number' + '\n')
train_file.close()
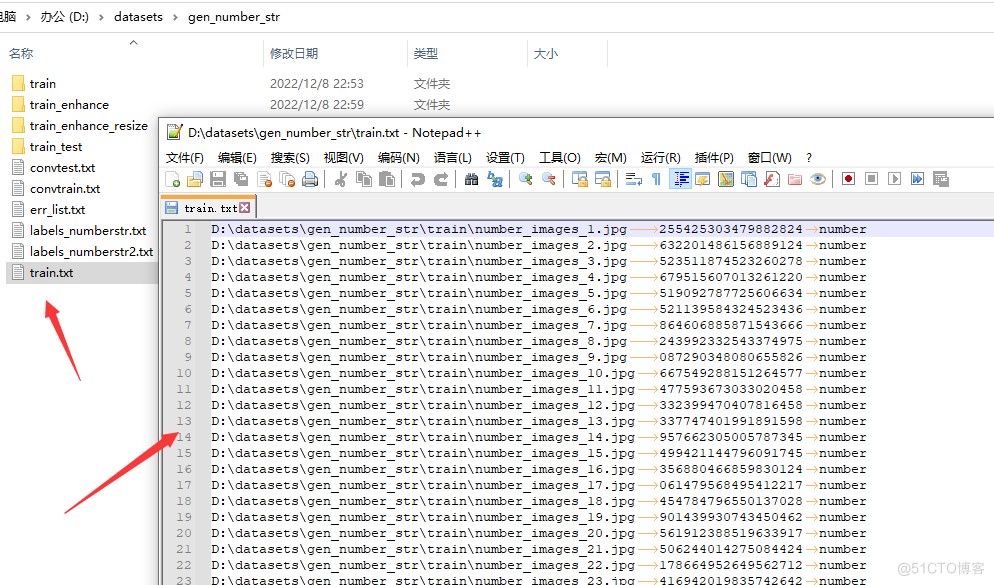
转移图像:
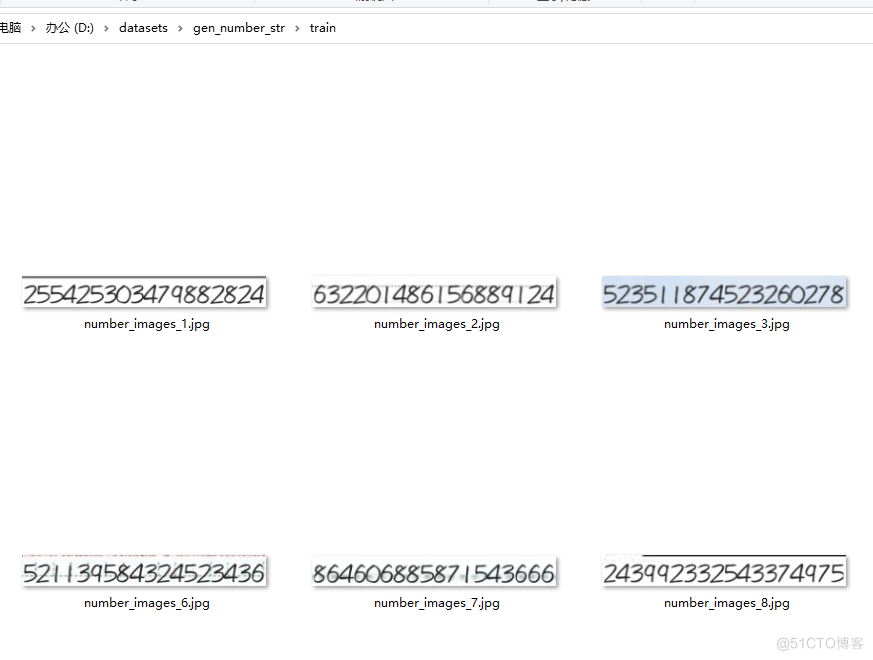
列表文件:
文章来源: https://blog.51cto.com/u_8681773/6004679
特别声明:以上内容(图片及文字)均为互联网收集或者用户上传发布,本站仅提供信息存储服务!如有侵权或有涉及法律问题请联系我们。
举报


